Milestone 1.1 - Deploying a contract
We are building Aztec 3 as transparently as we can. The documents published here are merely an entry point to understanding. These documents are largely complete, but unpolished.
If you would like to help us build Aztec 3, consider reviewing our GitHub to contribute code and joining our forum to participate in discussions.
See here for draft milestones.
See here for an unfinished (but maybe helpful) contract deployment sequence diagram, and other tabs for other useful diagrams.
See here for more on Contract Creation.
Reminder of the milestone:
As a developer, I can write a Noir++ contract scope, which contains a collection of pure functions (circuits) (no state variables yet).
I can type
noir my_contract.nrto compile a Noir contract to a JSON abi (or, hand craft the JSON abi).I can type
aztec-cli deploy_contract my_contract_abi.jsonand have a contract deployed to my local network.I can type
aztec-cli get_code addressto verify my contract has been deployed successfully.
The aim is to keep the implementation as simple as possible. We want to achieve the appropriate state shift on L1, and avoid anything that feels like unnecessary boiler-plate, or just "vanilla engineering". We're avoiding databases, network io, optimisations etc. Most of the code in this milestone should be directly related to computing and making the requisite state shift, otherwise we maybe going out of scope.
Further explanation:
It'll basically require the infrastructure needed to maintain the contracts tree, and the ability to construct and insert a leaf into it:
Note: some other data will also need to be broadcast as calldata on-chain, for data availability purposes. E.g. the ACIR opcodes of each newly-deployed contract.
High Level Architecture
Greyed out components don't need to exist at all for this milestone, but basically everything will need to exist in some capacity (even if some parts are heavily simulated).

This spec uses snake_case for it's naming, however in the world of TypeScript we should adapt these names as appropriate to be camelCase.
Communications Layer
Although we often speak about "JSON RPC", this is a transport layer concept, and is not actually needed for this milestone.
The various services and modules should be defined as TypeScript interfaces. Functions that take arguments and return results. We will start by just implementing these interfaces directly, and running the stack as a single monolith. We can then implement them as individual services a bit later by just auto-generating the JSON RPC http client code and server handlers. We have this pattern already between e.g. falafel and halloumi. Halloumi can just be run as a module within the falafel process, or run as a separate service.
Proving System
There will be no proofs generated in early milestones. Functions that would normally build an actual proof can be skipped (or be no-ops). The simulators should produce output that is identical to a proof output, just without the actual proof data (e.g. just the public_inputs). The kernel simulator and rollup simulator, will use the exact same C++ circuit logic, only the simulator will use native machine types so it's fast.
Thinking About State
The lowest level system state is represented by one or more streams of data. In AC this was the calldata and the off-chain data. A3 will likely have it's state also represented as more than one stream of data. For this milestone we could just adopt a similar separation of data, although longer term some state might make it's way into danksharding blobs, and maybe some state won't go to the ethereum network at all.
Regardless, there should be a separation of concern between the stream of data, and how/where it's stored. Data should be stored unprocessed, in an implementation of a simple key-value store interface. So e.g. there maybe a component that when pointed at the rollup contract, stores the calldata for each rollup in a key-value implementation that just saves it to a file named by rollup number.
A higher level component can take those multiple streams of data, and reconcile them to produce another single stream of data, the full data to describe a single rollup. These tasks will be handled by the data archiver, allowing querying of the data archiver for rollups > n.
The Private Client will have different methods for acquiring the data needed to produce its own data streams (one stream of data per account, effectively filtering the full chain state down to just the events relevant to that account).
- Brute force.
- Nym message protocol.
- Oblivious Message retrieval.
- Hybrids and new wonderful things?
The output streams of these technologies are the same, making them interchangeable. This stream of data represents the state shifts from the perspective of a single account. For this milestone we will just brute force.
There are a few considerations to make when processing state:
- State events are immutable (save and forget, idempotent).
- New state events can arrive at any time (consumers need to wake-to-handle).
- It grows unbounded, meaning it won't scale to "load and process all state at once".
- Traditional stream/channel concepts lend themselves well to ingesting, transforming, and outputting state.
Think of something like "Go channels" in terms of design (our MemoryFifo was written to leverage this pattern). Whereas a stream is often thought of as a buffered stream of bytes, channels are more like a buffered stream of messages. The SDK in AC has an example of how to do this. The BlockDownloader is told to start from a certain block number. It will build up an internal buffer of rollups in its "channel" (queue) till it hits some limit. A consumer calls getRollup which will block until a rollup is returned. Thus the consumer can have simple "synchronous" control flow loop. The code can also then be run naturally against a fixed size data store (it would just never block). It can act as a simple transformer, ingesting a directory of files and outputting another directory of files. This should also make isolated unit testing simple.
From an account perspective, as we process the accounts data stream, we will need to process the data through a simulator to execute contract specific filtering logic. This kind of transform changes the stream of data events into a snapshot. The final data representation thus maybe a set of key-values where a key is a storage slot, and a value maybe e.g. the sum of all UTXOs (the accounts balance).
The takeaway of this is to not get carried away with high level databases and indexes at this point, but to think of data as streams of data with simple low level representations. The transformations should be simple, modular, easily testable, and reusable in different environments (via storage abstraction).
Interfaces and Responsibilities
It's important to define some key concepts as interfaces. These can be categorised as either data, or logic based interfaces.
Data interfaces are about retrieving and/or updating state. By using the right abstractions, it will be possible to:
- Mock sources of data for use in unit/integration tests.
- Keep logic narrowly scoped to dealing with specific bits of data.
- Avoid dealing with databases for now.
- Take shortcuts that allow us to focus on protocol development and not get bogged down in privacy concerns. e.g:
- Use a
SiblingPathSourcethat just queries the remotePublicClientfor a contracts sibling path. - This normally would be a privacy concern, but it may not be if:
- Technologies like Nym work out over the longer term.
- The dapp can provide the paths as they're immutable.
- Otherwise we can substitute in a local cache of the contract tree at a later date.
- Use a
Logic interfaces are about executing specific bits of functionality. By using the right abstractions it will be possible to:
- Mock and dependency inject functionality for use in unit/integration tests.
- Ignore the writing of network code for now.
- Allow complete flexibility in terms of which components run in process, and which become remote.
- Run the stack quickly as a monolith for development and integration testing.
KeyStore
Responsibilities:
- Holds and never exposes private keys.
- Provides sign/decrypt functionality.
Interface:
create_account(): PublicKey- Creates and stores a (ecdsa?) keypair and returns public key.
get_accounts(): PublicKey[]- Returns all the public keys.
sign_tx_request(account_pub_key, tx_request): Signature- Produces a signature over the given
tx_request.
- Produces a signature over the given
decrypt(account_pub_key, data, eph_pub_key): Buffer- Decrypts data with a shared secret derived from an account private key and given ephemeral public key.
- Will need to be scoped in some way, such that the user can authorize a particular domain, to decrypt a particular scope of data.
AztecRpcClient (Previously Wallet/Private Client)
Responsibilities:
- Shields any upstream entities (dapp) from private information.
- Shields any downstream entities (Public Client) from private information.
- Maintains an up-to-date view of required parts of the global state from state streams to generate a tx.
- Maintains an up-to-date view of state for accounts in a
KeyStore.
Interface:
create_account(): PublicKey- Forward to
KeyStore
- Forward to
get_accounts(): PublicKey[]- Forward to
KeyStore
- Forward to
sign_tx_request(account_pub_key, tx_request): Signature- Forward to
KeyStore
- Forward to
simulate_tx(tx_request): SimulationResponse- Simulates the execution of a transaction. Returns:
- If the simulation succeeded.
- The
public_inputsof the kernel circuit. - In the future, gas estimates.
- Simulates the execution of a transaction. Returns:
create_tx(tx_request): Tx- Simulates the execution of a transaction to produce all data needed to generate a proof.
- Generates and returns the actual kernel proof.
send_tx(tx): void- Forwards the given tx to the
PublicClient.
- Forwards the given tx to the
PublicClient
Responsibilities:
- Acts largely as a facade to sub-systems.
- Provide methods for access Merkle Tree data (
SiblingPathSource). - Provide methods for requesting storage slot data for public state.
- Provide methods for requesting published rollup data (
RollupSource). - Receives txs and broadcasts them to the network via the
P2PClient.
Interface:
send_tx(tx)- Forwards the tx to the tx pool via
send_tx.
- Forwards the tx to the tx pool via
get_rollups(from, take)- Returns all rollup data in the requested range.
get_sibling_path(tree_id, index): SiblingPath- Returns the sibling path for the given index in a given tree.
get_storage_slot(address): Buffer32- For public state, we can request values at given storage slot addresses.
P2PClient
Responsibilities:
- Receives txs from the
PublicClient. - Receives txs from other
P2PClientinstances in the network. - Verifies received txs meet criteria to be added to the pool.
- Forwards all valid txs to other
P2PClientinstances in the network. - Receives rollups and purges settled or now invalid txs from local pool.
- Purges txs that are older than a certain threshold from the local pool.
Interface:
send_tx(tx)- Verifies the
tx, if valid, add to local pool and forward to other peers.- Passes proof verification.
- No conflicting commitments/nullifiers in tx pool and existing trees.
- Sane fee.
- Txs data root reference is still within the window (Tree of data roots).
- Verifies the
get_txs(): Tx[]- Returns all transactions in the transaction pool.
send_proof_request- TBD. Not for this milestone.
get_proof_requests- TBD. Not for this milestone.
SiblingPathSource
Responsibilities:
- Returns the sibling path for the given
tree_idat the given leafindex. - Can be injected into any context that requires path queries for a particular tree. Might be backed by implementations that call out to a server (where privacy doesn't matter, or during early development), or leverages some privacy tech (query via Nym), or could just point to a local
WorldStateSynchroniser.
Interface:
get_sibling_path(tree_id, index): SiblingPath
RollupSource
Responsibilities:
- Can be queried for
Rollupdata.
Interface:
get_latest_rollup_id()get_rollups(from, take): Rollup[]
RollupReceiver
Responsibilities:
- Given the necessary rollup data, verifies it, and updates the underlying state accordingly to advance the state of the system.
Interface:
process_rollup(rollup_data): boolean
TxReceiver
Responsibilities:
- Receives a tx, performs necessary validation, and makes it available to
SequencerClientinstances for rolling up.
Interface:
send_tx(tx): boolean
TxPool
Responsibilities:
- Gives a view of the pending transaction pool.
Interface:
get_txs(): Tx[]
Module Implementation Notes
Noir
These tasks are lower priority than providing a handcrafted ABI.
- The ability for a dev to enclose a collection of Noir functions in a 'contract scope'.
- The ability to create a Noir contract abi from the above.
Design a Noir Contract ABI, similar to a Solidity ABI which is output by Solc (see here). It might include for each function:
- ACIR++ opcodes (akin to Solidity bytecode).
- Function name and parameter names & types.
- Public input/output witness indices?
- Sourcemap information, allowing building of stack traces in simulator error cases.
aztec-cli
Provides the aztec-cli binary for interacting with network from the command line. It's a thin wrapper around aztec.js to make calls out to the client services. It's stateless.
aztec.js

Should provide sensible API, that provides the following functionalities. Start by writing the single e2e test that will check for the successful contract deployment. We don't need to get this perfect, but think hard about making the process feel very natural to a user of the library.
aztec.js should always be stateless. It offers the ability to interact with stateful systems such as the public and private clients.
The analogous AC component would be the AztecSdk (wraps the CoreSdk which is more analogous to the private client).
- Allows a user to create an Aztec3 keypair. Call
create_accounton Wallet. - Create a
Contractinstance (similar to web3.js), given a path to a Noir Contract ABI. - Construct
tx_requestby calling e.g.contract.get_deployment_request(constructor_args). - Call wallet
sign_tx_request(tx_request)to get signature. - Call
simulate_tx(signed_tx_request)on the Private Client. In future this would help compute gas, for now we won't actually return gas (it's hard). Returns success or failure, so client knows if it should proceed, and computed kernel circuit public outputs. - Call
create_tx(signed_tx_request)on Private Client to produce kernel proof. Can be skipped for this milestone. In future should be able to generate either mock (few constraints) or real proof. - Call
send_tx(tx)on Private Client to send kernel proof to Public Client. Get back a receipt. - Wait until the receipt is settled with repeated calls to
get_tx_receipton the Private Client.
ethereum.js
L1 client library. No ethers.js. Uses our existing and new L1 client code.
TestKeyStore
Interfaces Implemented:
KeyStore
Implementation notes for this milestone:
- Exposes a single account, created by a private key given in the ctor, that defaults to some test key.
- Can be used as both the spending and decryption key for early development.
AztecRpcServer (Previously Wallet/Private Client)

Implements:
AztecRpcClient(The server is a client, when used directly)
Injected:
KeyStore
Implementation notes for this milestone:
- Avoid saving any state for now. Just resync from the
PublicClienton startup. - Avoid needing to sync the merkle trees for now. Just use
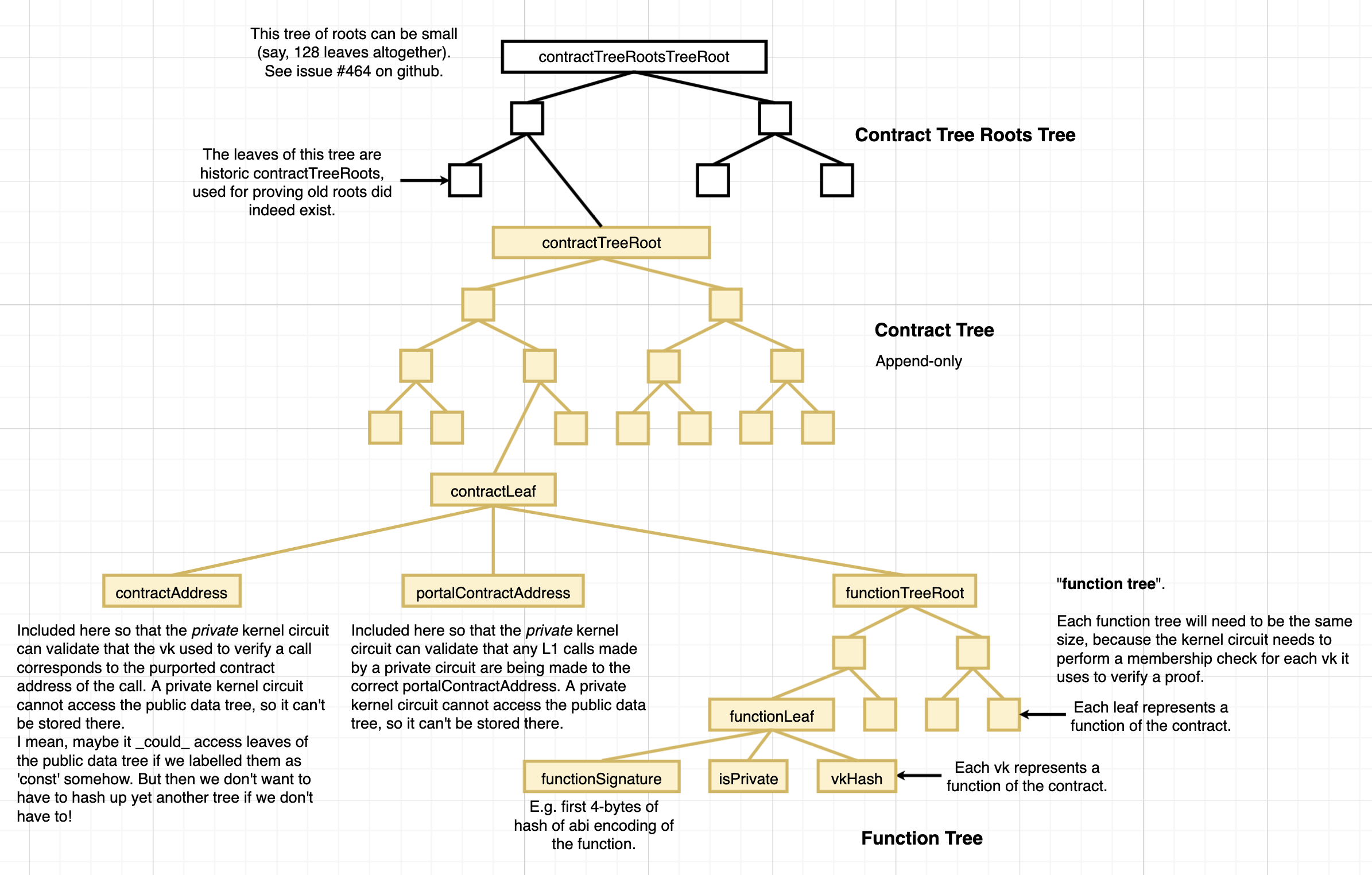
SiblingPathSourcethat queries the paths from thePublicClient. simulate_tx- Can compute the contract's leaf (which will be inserted into the contract tree). See diagram linked at top of page.
- Can spin-up a simulator instance for the constructor function.
- (Note, executing an interesting constructor function is not until the next milestone, but we still need to execute a no-op constructor function for a contract deployment, since the public inputs of the constructor carry some contract deployment info, and need to passed into the kernel circuit).
- Simulator will check whether the tx will succeed. It will return all public inputs/outputs.
- Can collect/generate additional data required for kernel circuit execution.
- Can pass the fake constructor proof, public inputs, and other kernel circuit data into a kernel simulator.
- Returns if the simulation succeeded, and the public inputs/outputs of the kernel circuit.
create_tx- For this milestone, will just do the same as
simulate_tx. - Returns a
txthat can be sent tosend_txwith everything but actual proof data.
- For this milestone, will just do the same as
send_tx- Forwards the given tx to the Public Client.
PublicClientImpl

Implements:
PublicClient
Injected:
P2PClientRollupSourceMerkleTreeDb
Implementation notes for this milestone:
- Mostly acting as a facade for other components, forwards requests as necessary.
- A
WorldStateSynchroniserwill ingest rollups from theRollupSourceand maintain an up-to-dateMerkleTreeDb.
MemoryP2PClient
Implements:
P2PClient
Injected:
RollupSourceMerkleTreeDb
Implementation notes for this milestone:
- For this milestone there won't be any p2p network.
- Perform relevant validations possible in this milestone (e.g. check no tree conflicts, skip proof verification).
- Purge relevant txs from pool on rollup receipt.
- Store txs in an in memory map of txId -> tx.
Sequencer Client

Responsibilities:
- Wins a period of time to become the sequencer (depending on finalised protocol).
- Chooses a set of txs from the tx pool to be in the rollup.
- Simulate the rollup of txs.
- Adds proof requests to the request pool (not for this milestone).
- Receives results to those proofs from the network (repeats as necessary) (not for this milestone).
- Publishes L1 tx(s) to the rollup contract via
RollupPublisher.
For this milestone, the sequencer will just simulate and publish a 1x1 rollup and publish it to L1.
MerkleTreeDb
Implements:
SiblingPathSource
Implementation notes for this milestone:
Closest analogous component in AC is the WorldStateDb in bb.js. We can configure the backing store (probably leveldb) to be an in-memory only store. We don't need persistence, we will rebuild the tree at startup. This will ensure we have appropriate sync-from-zero behaviour.
Responsibilities:
- "Persists" the various merkle trees (configurable).
- For this milestone 1.1, we'll need the following trees:
- Contract Tree
- Contract Tree Roots Tree (the tree whose leaves are the roots of historic rollups' contract trees)
- Nullifier Tree (so that the contract address can never be re-registered in a future deployment)
- Note: Suyash has implemented C++ for the 'new' kind of nullifier tree.
- For this milestone 1.1, we'll need the following trees:
- Provides methods for updating the trees with commit, rollback semantics.
- Provides methods for getting hash paths to leafs in the trees.
Interface:
get_rootget_num_leavesget_sibling_pathappend_leaves
WorldStateSynchroniser
Injected:
RollupSourceMerkleTreeDb
Responsibilities:
- Receives new rollups from the
RollupSourceand updates trees in theMerkleTreeDb.
Rollup Archiver
Implements:
RollupSource
Responsibilities:
- Pulls data in from whatever sources are needed, to fully describe a rollup e.g.
- L1 calldata (
provessRollupandoffchainDatafor this milestone.) - ETH blobs (not before they are released).
- Other sources that have archived historical ETH blobs (not before they are released).
- L1 calldata (
- Combines these sources of data to describe a
Rollup. - Can be queried for the rollup data.
Interface:
get_latest_rollup_idget_rollups(from, take)
Rollup Publisher
Implements:
RollupReceiver
Implementation notes for this milestone:
- We can leverage most of the logic from Falafels old
RollupPublisher. - On receipt of a rollup, will publish to L1 and respond with success or failure.
Rollup Smart Contract
Interface:
processRollup(proofData, l1Data)offchainData(data)
Implementation notes for this milestone:
The rollup contract in AC holds data in two places that are reconciled when processing the rollup. The calldata passed into the processRollup function, and the calldata passed into the offchainData function. They were separated, as only the data given to processRollup is needed to ensure rollup liveness (i.e. if the "offchain data" were not published, we could still produce rollups). Ultimately the plan was to move the offchain data off of L1 altogether to reduce costs.
For this milestone, we will want to leverage a similar separation of data. The data to processData will consist of:
proofData- The proof data to be fed to the verifier. Likely will have a public inputs that represent:- The hash of the data in the offchain data (should use whatever commitment scheme Eth Blobs will use).
- Recursion point fields.
l1Data- Data that is needed for making L2 - L1 function calls.
For logic:
- Can receive a rollup proof and verify it (verifier just returns true for this milestone).
- Can update the state hash (which would only represent an update to the contract tree, at this milestone).
For offchainData:
- Receives relevant calldata that needs to be broadcast. For contract deployment, this might be:
- Acir opcodes.
- Constructor arguments.
- Contract address & contract leaf.
Kernel Circuit functionality
- Can validate the signature of a signed tx object.
- Can verify a 'previous' mock kernel circuit (this code is already in there).
- Can verify the constructor function's proof (this functionality is already in there).
- Can check contract deployment logic. (Note: it won't contain checks for private circuit execution logic, as that's for a future milestone).
Rollup Circuit functionality
- TODO: more discussion needed to understand exactly what's needed here.
- Can verify a kernel circuit proof
- Can compute the contract's address
- Can compute a 'nullifier' for the contract's address, to prevent it being used again (possibly defer this, because we don't want to care about a nullifier tree in this milestone).
- Can compute the contract leaf for the contract (see diagrams).
- Can insert the contract's leaf into the contract tree.
- Can insert the contract tree's root into a "tree of contract tree roots".
- ???? Verifies the ACIR Verification proof (see Contract Creation doc by Zac)
Glossary
witness: Any value within the circuit, by default these are private, and thus not visible on the proof. Some witnesses may be made public (visible on the proof), at which point they also becomepublic_inputs.[circuit_]input: Data that is computed outside the circuit and is fed in at the beginning as awitness. Note: if the context of this relating to a 'circuit' is already clear, we can omitcircuit_, as is done in theaztec3_circuitsrepo.oracle_input: Data that, during execution, is fetched from the oracle, and made awitness.computed_public_input: Data that is computed within the circuit, and set to be apublic_input.public_input: Data that is set to be public by the circuit. This could include somecircuit_inputdata, and/or somecomputed_public_inputdata, and/or someoracle_inputdata.